13.04.2026 6 min Lesezeit
Wie KI unsere Teststrategie transformiert hat – von Cypress zu automatisierten Playwright-Tests

Nachdem wir im ersten Teil unserer Serie einen Überblick über die
KI-Landschaft, wichtige Begriffe und unsere ersten Tool-Tests gegeben haben, gehen wir jetzt in die Praxis.
In diesem Beitrag werfen wir einen tiefen Blick in unseren Tech-Stack und räumen mit einem alten Schmerzpunkt auf: lückenhaften Test-Suiten.
Wir standen vor der Wahl, weiterhin wertvolle Ressourcen in komplizierte Cypress-Workarounds zu stecken oder unsere Strategie mithilfe von KI grundlegend zu überdenken.
1. Ausgangslage: Tests als notwendiges Übel
Am Anfang hatten wir nur eine Handvoll Cypress-Tests. Gerade genug, um die wichtigsten Funktionen der riskantesten Projekte abzudecken. Die Abdeckung war gering, und es gab nur eine verantwortliche Person, die immer wieder Probleme der bestehenden komplizierten Cypress-Tests behoben hat.
IFrames, lange Wartezeiten und die Abhängigkeit von Drittanbieter-Plugins waren wiederkehrende, nervenaufreibende Probleme mit Cypress. Tests wurden eher als lästige Pflicht und nicht als echtes Sicherheitsnetz betrachtet.
Je größer die Codebasis wird, desto vorsichtiger muss man bei Änderungen werden. Refactoring wird zum Risiko.
Wir wussten, wir müssen etwas ändern. Manuelle Tests deckten nicht länger alle Probleme auf und wir hatten schlicht nicht die Ressourcen, um für jedes Feature sofort einen Cypress-Test zu schreiben.
2. Erste Experimente mit Junie
2025 hatte ich die Gelegenheit, den KI-Code-Agenten Junie von JetBrains ausgiebig zu testen. Das Szenario Testautomatisierung war für mich ein gutes Beispiel, um für mein Projekt Cypress-Tests zu schreiben.
Bei meiner Recherche, für die ich gefühlt das halbe Reddit durchforstet habe, stieß ich auf den Playwright MCP Server. MCP steht für “Model Context Protocol”, einen offenen Standard, der es KI-Agenten ermöglicht, externe Tools und Datenquellen strukturiert zu nutzen.
Im Kontext von Tests bedeutet das: Der KI-Agent kann den Browser direkt steuern, den DOM inspizieren, Selektoren analysieren und verifizierten Code zurückliefern.
Anfangs habe ich noch A4-Seiten füllende Prompts geschrieben, was sehr zeitaufwendig war. Es wurden sehr viele Token verbrannt (MCPs verbrauchen durch den DOM-Snapshot viele Token). Ich habe sehr viele verschiedene Workflows ausprobiert, bis ich einen guten Self-Healing-Prozess mit Hot-Deployment-Setting hatte.
Das Ergebnis war solide, aber noch nicht überzeugend. Dennoch war das der Moment, an dem ich realisierte: Wir brauchen kein Cypress mehr.
Playwright bietet eine deutlich bessere Integration für KI-gestütztes Testen. Cypress hat zwar KI-Funktionen angekündigt, diese sollen jedoch kostenpflichtig werden.
3. Die Entscheidung: Migration zu Playwright
Die Entscheidung für Playwright war am Ende eine strategische. Ausschlaggebend waren vor allem drei Faktoren:
Bessere Integration von KI-Tools: Etwa durch MCP-Support und die Playwright CLI von Microsoft; im Gegensatz zu den proprietären und künftig kostenpflichtigen KI-Features auf der Cypress-Roadmap.
Technische Überlegenheit: Parallele Ausführung als Standard, native Unterstützung für Cross-Origin-Testing, vollständige Session-Kontrolle, IFrame-Support ohne Plugins und eine API, die näher an nativem JavaScript/TypeScript ist.
Open Source & Performance: Playwright ist komplett quelloffen, extrem performant und deutlich weniger fehleranfällig.
Was noch fehlte, war der Beweis, dass die Migration auch in der Praxis funktioniert. Dafür haben wir ein bewährtes Format genutzt: den internen Hackathon.
4. Der Hackathon: Migration unter echten Bedingungen
Während unseres internen Hackathons haben wir die Migration von Cypress zu Playwright anhand eines Projekts mit 19 Tests durchgeführt. Dabei traten Junie, OpenAI Codex und Claude Code als KI-Assistenten im direkten Vergleich gegeneinander an.
Das Ergebnis: Die vollständige Migration eines bestehenden Projekts in nur drei Tagen.
Diese drei Tage waren aber kein reines Umschreiben von Code. Wir haben intensiv an Prompts und Workflows gearbeitet, verschiedene Ansätze ausprobiert und die Tools unter realen Bedingungen verglichen. Es war ein steiler Lernprozess, der uns zeigte, wie KI im Testkontext wirklich produktiv eingesetzt werden kann.
Entscheidend war dabei nicht nur das Tempo, sondern auch die Qualität. Claude Code erwies sich als besonders stark darin, Kontext zu wahren und konsistent mit unseren bestehenden Patterns zu arbeiten. Die generierten Tests waren nicht bloß generisch, sondern fügten sich nahtlos in unsere Codebasis ein.
5. Stabilisierung: Regeldateien als Teamgedächtnis
Nach dem Hackathon kam die eigentliche Arbeit: die Migration produktionsreif zu machen. Bis dahin hatten wir verschiedene Tools parallel getestet, doch schnell stießen wir bei Junie an seine Grenzen: Es war langsam, ließ sich im Prozess kaum lenken und lieferte schwankende Qualität. Mal passte der generierte Code gut, mal nicht, ohne dass man klar eingreifen konnte.
Claude Code bot uns drei Dinge, die den Unterschied machten:
CLAUDE.md: Eine projektspezifische Regeldatei, die der KI genau vorgibt, wie wir arbeiten. Kein Raten mehr, kein Neulernen bei jedem Start. Diese Dateien sind unser Teamgedächtnis. Was einmal gelernt wurde, geht nicht verloren.
Eigene Agenten: Spezialisierte KI-Workflows, die wir selbst definieren und die komplexen Aufgaben eigenständig koordinieren.
Skills: Wiederverwendbare Anweisungsblöcke für wiederkehrende Prozesse, vom Planen eines Features bis zum Code-Review.
Ein konkretes Beispiel aus der CLAUDE.md
Wir haben darin festgelegt, dass ausschließlich getByTestId() als Selektor erlaubt ist. Alternativen wie getByText, getByRole, filter({ hasText: ... }) oder direkte CSS-Klassen sind ausgeschlossen. Klare Regeln, die Claude Code zuverlässig einhält.
Parallel dazu haben wir den MCP-Server durch die Playwright CLI von Microsoft ersetzt. Sie ist token-effizienter, stabiler und performanter. Tests, die früher fragil waren, wurden mit diesem Setup deutlich zuverlässiger.
6. Heute: Tests entstehen automatisch
Das vielleicht beeindruckendste Ergebnis ist, wie selbstverständlich Tests mittlerweile in unserem Entwicklungsprozess geworden sind. Wenn wir Claude Code nutzen, werden Playwright-Tests auf Basis der jeweiligen Anforderungen als fester Bestandteil des Feature-Plans eingeplant.
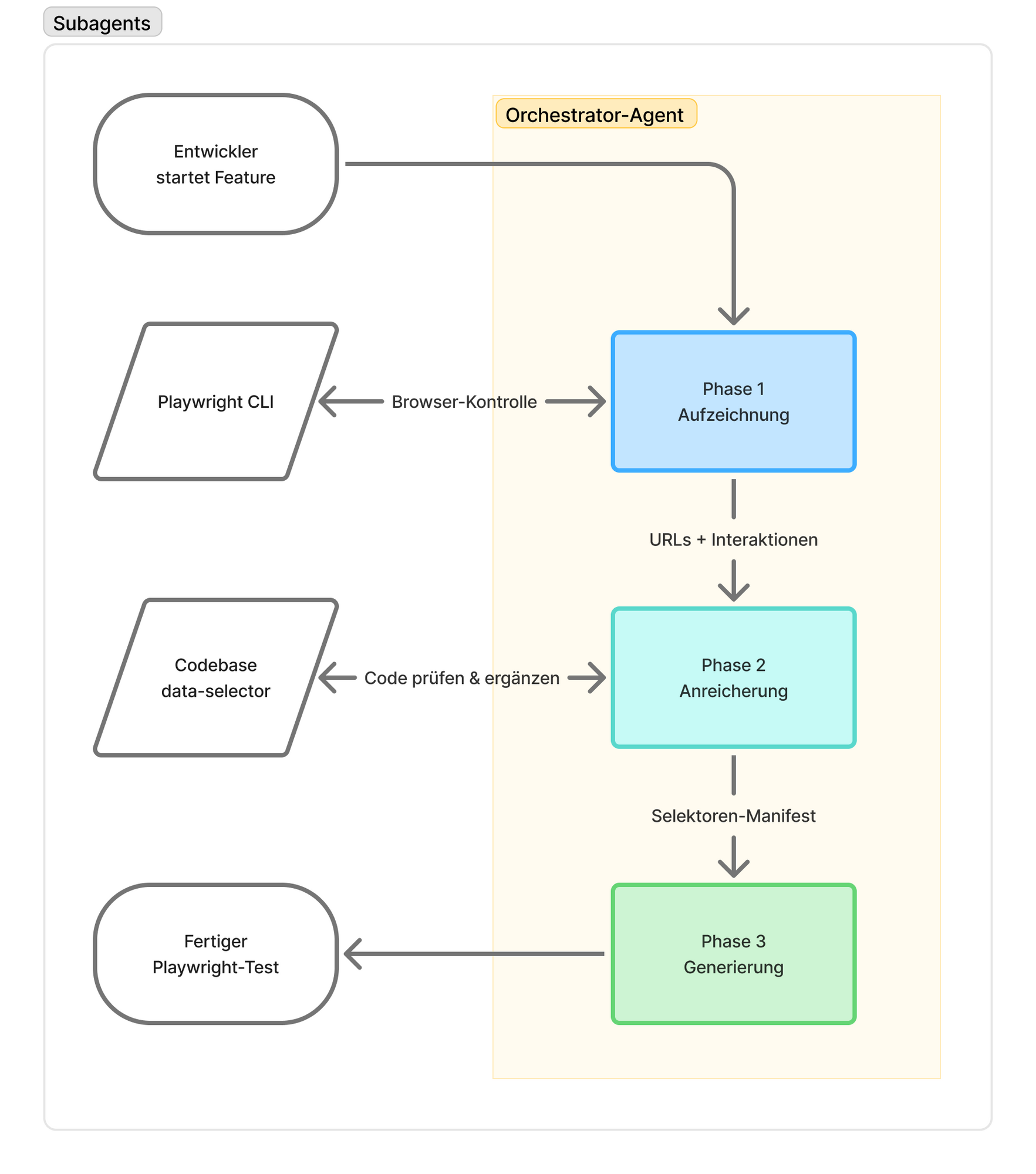
Wir haben dafür einen eigenen Orchestrator-Agenten geschrieben, der automatisch Playwright E2E-Tests generiert, indem er drei Phasen koordiniert:
Aufzeichnung: Er zeichnet den Browser-Ablauf live über die Playwright-CLI auf und hält exakte URLs sowie UI-Interaktionen fest.
Anreicherung: Er delegiert an einen zweiten Agenten, der prüft, ob alle berührten Elemente ein data-selector-Attribut besitzen, und ergänzt diese bei Bedarf direkt im Code.
Generierung: Abschließend übergibt er das resultierende Selektoren-Manifest an einen dritten Agenten, der dann den fertigen, sauberen Testcode schreibt.
Tests sind dadurch kein nachträglicher Schritt mehr. Sie entstehen parallel zum Feature. Das klingt klein, ist aber ein kultureller Wandel: Das Team denkt nicht mehr in der Reihenfolge „Feature fertig → Tests schreiben“, sondern „Feature entwickeln = Tests inklusive“.
7. Ausblick: Tests als Fundament für Refactoring
Unser nächstes Ziel ist eine hohe, flächendeckende Testabdeckung. Nicht als Selbstzweck, sondern als strategisches Fundament. Denn eine solide Testsuite ermöglicht etwas, das viele Teams scheuen: selbstbewusstes Refactoring.
Wenn bei jeder Änderung automatisch überprüft wird, ob etwas kaputt gegangen ist, sinkt das Risiko von Regressionen dramatisch. Technische Schulden können abgebaut werden, ohne dass das Team zittern muss.
Hohe Testabdeckung ist kein Qualitätsluxus, sondern sie ist die Voraussetzung dafür, dass eine Codebasis langfristig wartbar bleibt.
KI macht es heute möglich, dieses Fundament zu legen, ohne den Entwicklungsprozess mit manuellem Mehraufwand zu belasten. Das ist die eigentliche Transformation unserer Arbeit.
Neues aus der Kategorie "Wissen"